

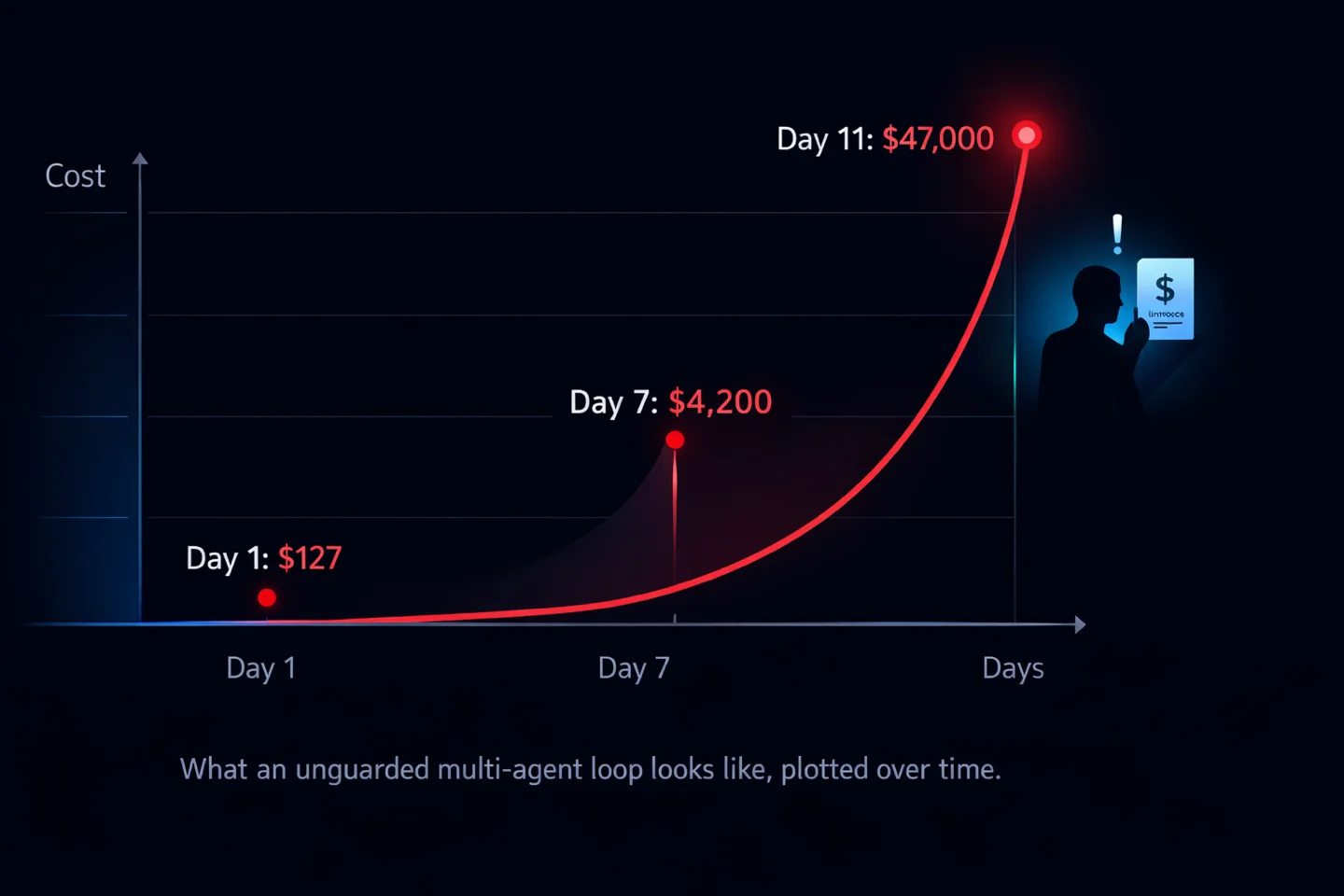
A founder I spoke with recently left an AI agent running over a long weekend. He’d wired it up to monitor a competitor, pull pricing data, and update a shared spreadsheet. Day one: $127 in API and tool costs. Tuesday: $4,200. By the following Friday, the invoice had climbed to forty-seven thousand dollars and counting.
Nothing about the agent was broken in the traditional sense. It wasn’t hallucinating. It wasn’t making bad decisions. It was doing exactly what it was told: retrieving a page, parsing it, writing a row, then starting over. The problem was a subtle retry loop, compounded by a tool that billed per call, running against a model with no sense of what it had already done this hour.
Agent cost runaway is the failure mode that nobody demos. It’s also the one that will put a founder off autonomous AI faster than any hallucination ever will.
This post is about why unguarded agents blow up, and the three-layer guardrail architecture that stops it.
Why agents burn money
Three failure modes account for almost every runaway cost story we’ve seen.
Loops. The agent makes a tool call, gets a result it doesn’t recognize as a success, tries again. Some models “self-correct” by retrying with small variations 50 times, 500 times, until some upstream limit stops them. In a multi-agent setup where agents call agents, loops compound multiplicatively.
Non-idempotent retries. The agent times out on a call to an external API. It retries. The first call actually succeeded; the response just didn’t get back in time. Now the same action has been taken twice, or twenty times. For search APIs or LLM calls this wastes money. For booking, payment, or messaging APIs it wastes money and creates real-world messes.
Over-eager tool use. The agent isn’t looping, but its goal is vague enough that “thorough” means “call every available tool, then call them again just in case.” This is the mode where a research task that should cost $5 costs $500, because the agent ran 30 web searches where 2 would have done.
The common thread: the agent’s reasoning alone won’t save you. LLMs don’t have a reliable internal model of cost, time, or how many times they’ve already done something. Expecting the agent to self-regulate is how you get the $47,000 invoice.
The gate model
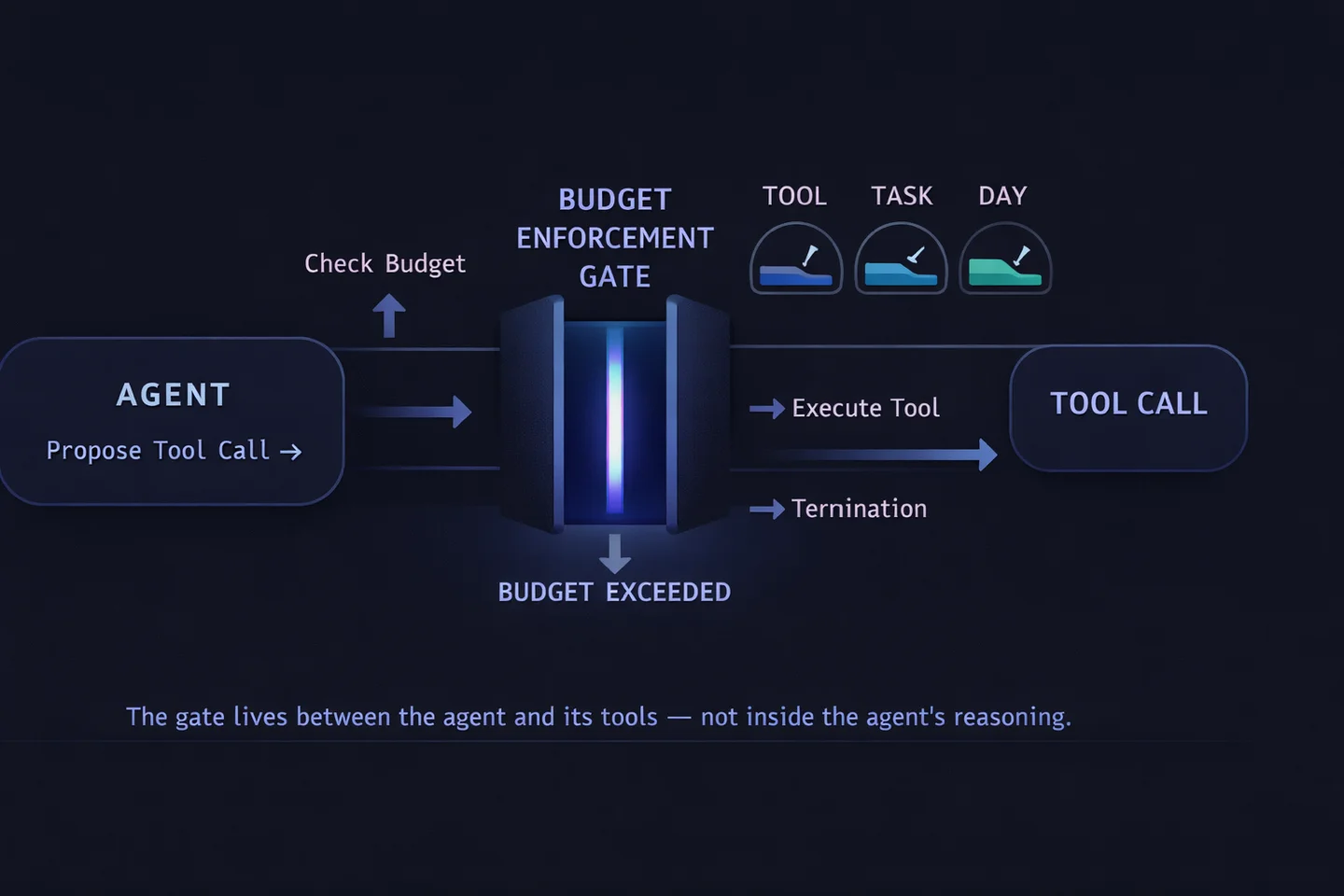
The fix is structural, not cognitive. You put a gate between the agent and the tools it can use, and the gate, not the agent, enforces budgets.
Every tool call the agent wants to make is a proposal that has to pass through the gate. The gate checks three budget windows (per tool, per task, per day), a loop detector, and an idempotency key. If any check fails, the call is rejected before it touches the outside world. If all pass, the call executes and the gate writes a row to the audit log.
This is the pattern from financial systems, not from AI, and that’s the point. We don’t trust our LLM agents with budgets any more than banks trust their tellers with them. We enforce the rules at a layer the model can’t bypass.
The three layers
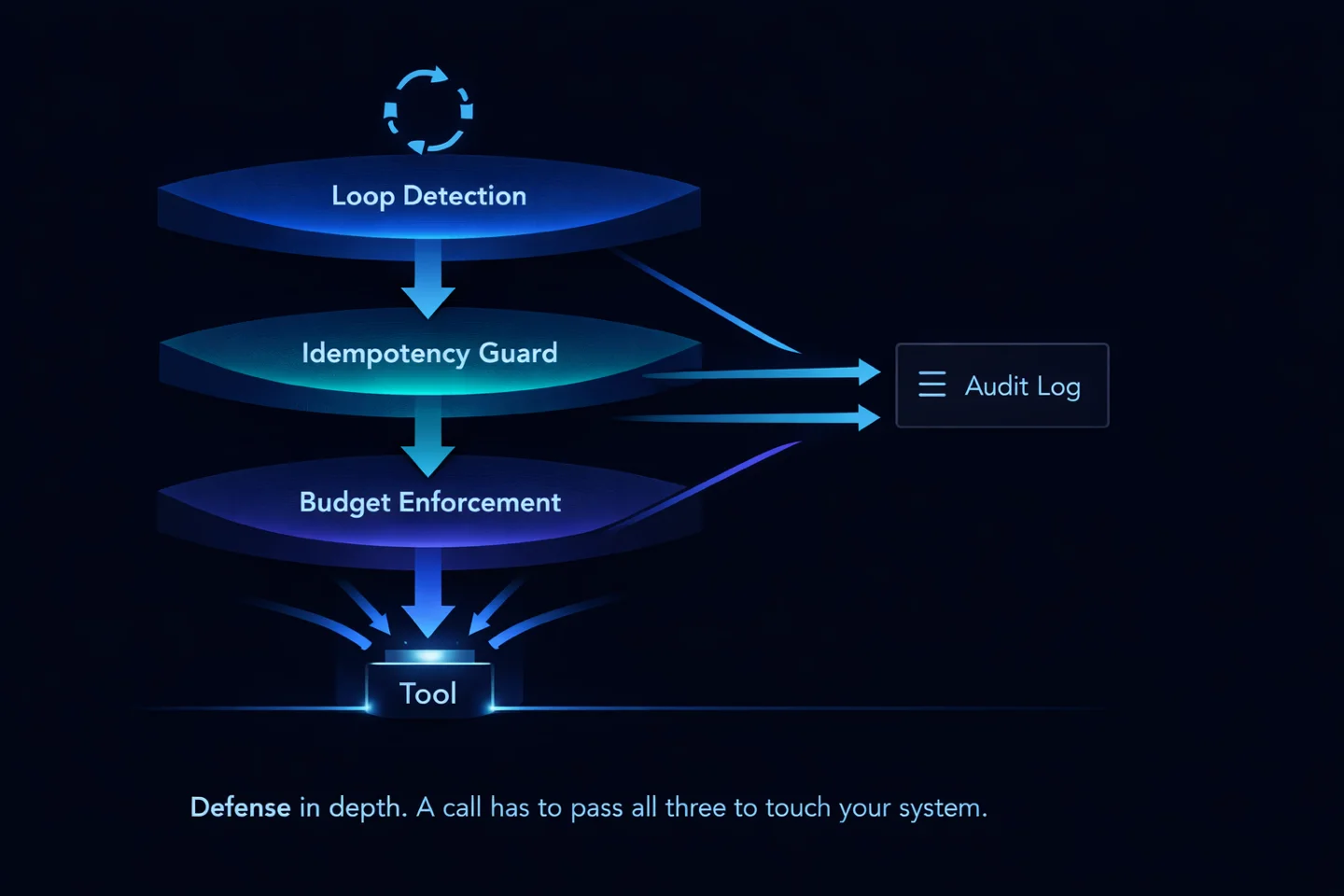
The gate is a composition of three independent checks. Each solves one specific class of failure. They stack.
1. Loop detection. Hash every proposed tool call with its arguments. If the same hash has been seen N times in the last M minutes, the call is rejected and the agent gets an explicit “you’re in a loop” signal back. Tuning N and M depends on the tool. For a web search, N=3 in a 60-second window is aggressive but safe; for a file write, even N=2 is worth flagging. The point is to fail fast before the loop costs anything meaningful.
2. Idempotency guard. Before any non-read-only tool call, compute an idempotency key from the semantic intent (“send email to X with subject Y”) rather than the literal request bytes. If the key has been seen recently and the prior call succeeded, skip execution and return the cached result. This is what catches timeout-retry doubles. The cost of maintaining the idempotency cache is orders of magnitude lower than the cost of a double-booked flight or a twice-sent email.
3. Budget enforcement. Every call decrements three budgets at once: per-tool, per-task, and per-day. Per-tool stops a single expensive API from eating the budget. Per-task stops one goal from running away. Per-day is the global circuit breaker. When any budget hits zero, the gate rejects the call and surfaces a clear signal (not an opaque error) so the agent can either ask for more budget or stop cleanly.
All three write to a single audit log. Every decision, every rejection, every execution, timestamped, keyed, reconstructable. If the agent misbehaves, you can see exactly what it tried, what the gate did, and why.
What this does not solve
It’s worth being explicit about what this architecture does and doesn’t protect against. Three guardrails solve three specific classes of problem. Everything else still needs engineering.
Solved by the gate:
- Runaway cost from retries and loops
- Double-execution of non-idempotent operations
- Budget overruns across tool, task, and day boundaries
- Lack of visibility into what the agent actually did
Not solved by the gate:
- Bugs in the agent’s logic. If the agent plans a sensible call that has expensive downstream consequences, the gate will let it through, because it’s a sensible call. Planning quality is a separate problem.
- Prompt injection. A hostile document that tricks the agent into requesting a tool call you didn’t authorize will be executed if it falls within budget. Preventing this needs a separate allow-list and capability model.
- Misused credentials or overbroad tool scopes. The gate enforces how often the agent acts, not what it’s allowed to act on. Tool scopes, auth boundaries, and least-privilege access are a separate layer.
- Operator error. Setting a $10,000/day budget when the workload only justifies $50 is still a $10,000-a-day mistake. Budgets have to be set conservatively; the gate enforces them, but it doesn’t set them for you.

Why this matters now
The industry spent 2024 and 2025 learning that frontier models can plan and use tools. It’s spending 2026 learning what happens when that planning is wired up to a credit card without a meter on it.
The teams that ship agents that stay in production are the ones that treat this like banking infrastructure: every action logged, every budget enforced at a layer the reasoning can’t override, every call idempotent by default. It’s not glamorous engineering. It’s the engineering that keeps the lights on.
At Brainmox, the gate is a first-class part of the agent runtime. Budgets are set per user, per task, per tool. Loops are detected before the second call. Every outbound action is keyed and cached. The audit log is open. You can inspect any action the agent took and roll back anything that touched external state.
If you’re running agents in production and don’t have a gate between your model and your tool calls, tonight is a good night to add one.