

You tell your AI everything.
Your business strategy. Your revenue numbers. Your hiring plans. Your personal frustrations. Your health questions. Your relationship problems. The draft email you rewrote six times before sending. The competitor analysis you wouldn’t share with your own board yet.
And where does all that information go?
Most AI companies would prefer you didn’t ask. The answer is uncomfortable: your data leaves your device, travels to remote servers, gets processed in data centers you’ve never seen, and is stored in ways you can’t audit. It sits alongside the data of millions of other users, managed by teams you’ll never meet, under policies that can change without notice.
This isn’t a conspiracy theory. It’s the fundamental architecture of cloud-native AI.
The convenience-privacy tradeoff nobody agreed to
Here’s the deal the industry has offered you: give us your data, and we’ll give you a smart assistant. It’s a trade most people accept without thinking. The AI is useful, the conversations feel private (it’s just you and a chat window, right?), and the privacy policy is long enough that nobody reads it.
But the math doesn’t work in your favor.
Every conversation, every uploaded document, every voice memo adds to a profile that lives on someone else’s infrastructure. The average power user of a cloud AI tool has shared over 100,000 words of personal and professional context to servers they don’t control. That’s more than most people write in a year. That’s not a chat log. That’s a diary.
And here’s the part that rarely gets discussed: the data doesn’t just sit there. It gets processed. It gets analyzed. In many cases, it gets used to train the next version of the model, which means your private thoughts become part of a system that serves millions of other people. Your competitive analysis could be informing someone else’s strategy. Your personal struggles could be shaping how the AI responds to a stranger across the world.

The real cost of this tradeoff isn’t visible until something goes wrong. A data breach. A policy change. A subpoena. A training data leak. By then, the information is already out of your hands, and there’s nothing you can do to pull it back.
What “local-first” actually means
Local-first isn’t a privacy feature you toggle on. It’s an architecture decision that makes privacy the default.
The idea is straightforward: your data starts and stays on your device. Processing happens locally first. Cloud services are optional, used only when you explicitly choose them. You own your data not because a company promises to respect it, but because it never leaves your possession in the first place.
This is how software used to work before everything moved to the cloud. Your documents lived on your hard drive. Your photos were on your camera roll. Your notes were on your phone. You didn’t need to read a privacy policy to know where your data was. It was right there, on the device in your hands.
The cloud era changed that equation. Convenience went up. Control went down. And most people didn’t notice the shift because the benefits were real and the costs were invisible.
Local-first architecture brings the control back without sacrificing the intelligence. Your AI can still be smart, still learn your preferences, still build context over time. It just does all of that on your device, under your control, with your permission.
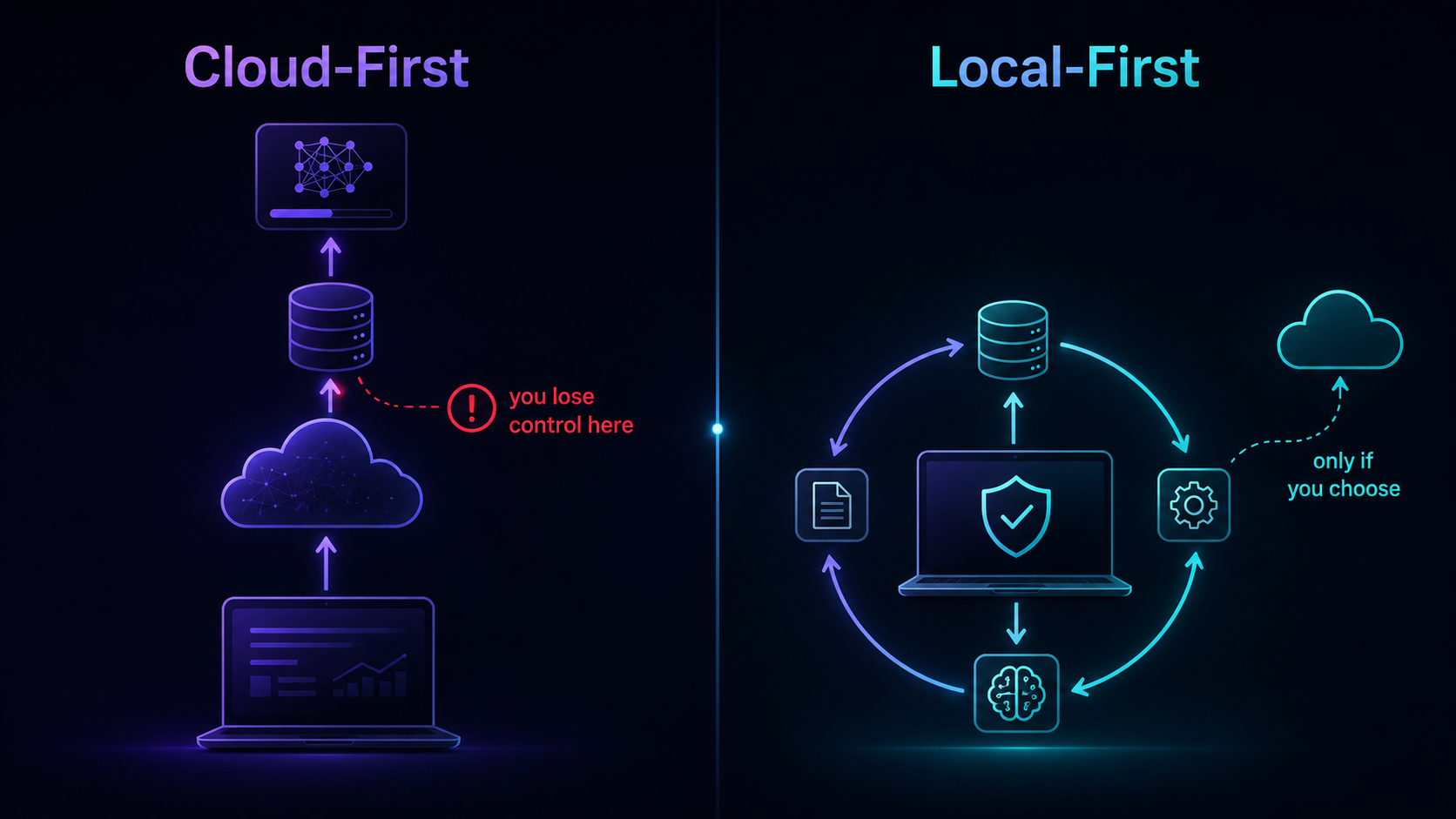
BrainMox is built this way from the ground up. Your memory, your preferences, your project context: all stored locally. You decide what syncs. You decide what stays. And because the architecture is local-first, there’s no backdoor for us to access your data even if we wanted to. We can’t see it. We don’t want to. It’s not our business model.
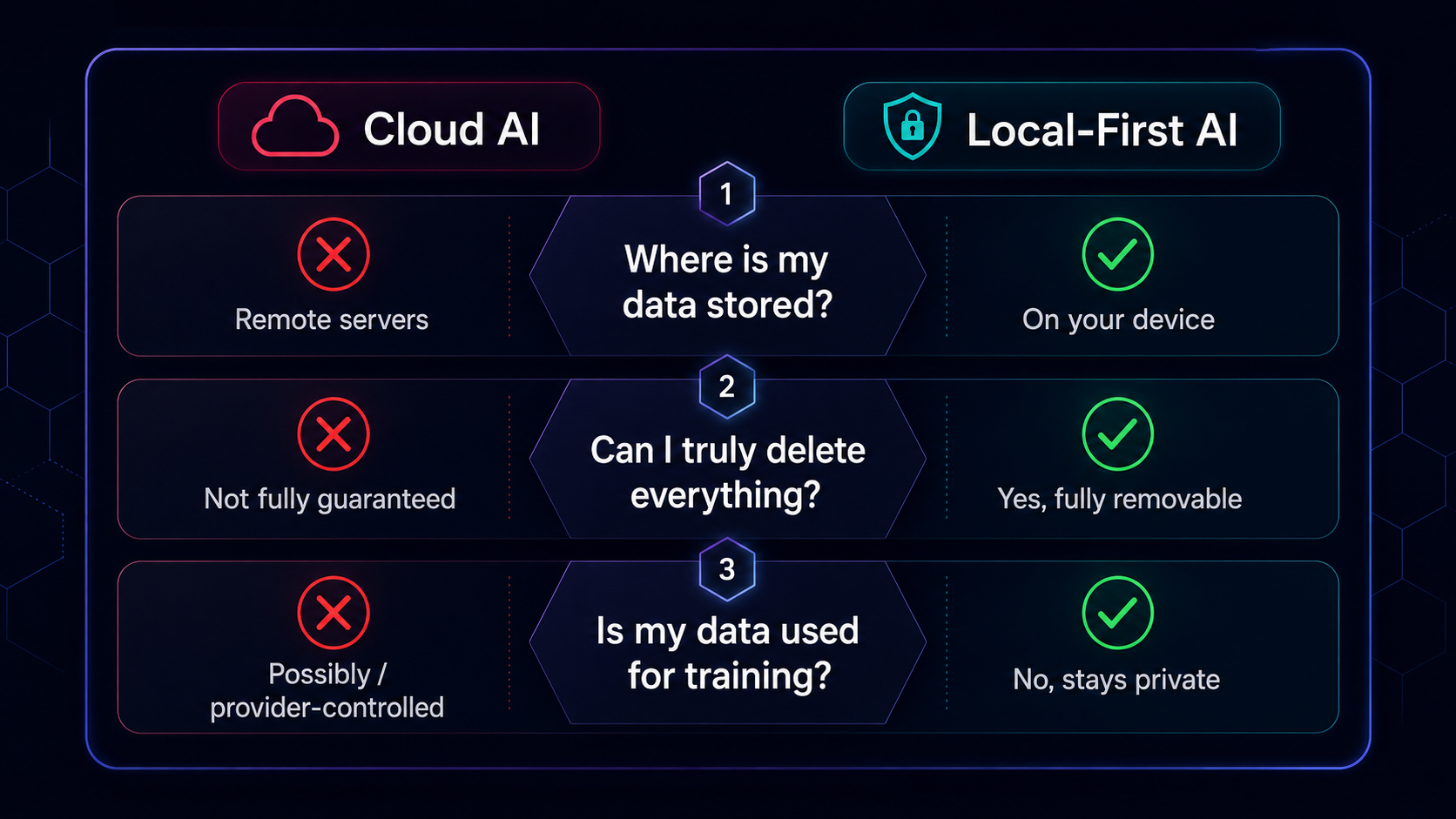
The three questions to ask any AI tool
Before you share your next conversation with an AI assistant, ask three questions. They’ll tell you everything you need to know about how seriously that tool takes your privacy.
1. Where is my data stored? If the answer is “our servers” or “the cloud,” your data is on infrastructure you don’t control. It’s subject to that company’s security practices, their employees’ access levels, their government’s jurisdiction, and their future business decisions. A company that stores your data can sell, share, or lose it. A company that never has your data can’t do any of those things.
2. Can I delete everything? Real deletion, not just “hidden from your view.” Many AI tools let you delete a conversation from your interface, but the data persists in backups, training sets, or analytics pipelines. If the company can still access your data after you hit delete, it’s not really deleted. Ask for proof. If they can’t provide it, assume the worst.
3. Is my data used for training? This is the question most AI companies dodge. Many use your conversations to improve their models. That means your private data becomes part of a system other people use. Some companies let you opt out, but the default is usually opt-in. And even when they say your data isn’t used for training, read the fine print. “We don’t use your data to train our models” and “we don’t use your data to improve our services” are two very different statements.
If an AI company can’t give you clear, direct answers to these three questions, the privacy bottom line is simple: your data is their data too.
Why we built BrainMox differently
We didn’t start with a chatbot and add privacy as an afterthought. We started with a question: what would an AI assistant look like if privacy was the foundation, not a feature?
The answer shaped every technical decision. Local-first storage means your data never touches our servers unless you explicitly send it somewhere. Persistent memory means the AI gets smarter about you over time, but that intelligence lives on your machine, not ours. Real identity means the AI knows who it is and who you are, without broadcasting either to the world.
This approach has tradeoffs. Building local-first is harder than building cloud-first. It requires more engineering, more thoughtful architecture, more work upfront. But the result is an AI that respects your privacy not because of a policy, but because of how it’s built. Policies can change. Architecture is permanent.
And because your data stays local, we can’t monetize it. We can’t sell it. We can’t mine it for insights. Our business model is simple: you pay for the product. That’s it. No hidden data economy running underneath the surface.
The bottom line
Your AI assistant knows more about you than your therapist. It knows your work projects, your personal goals, your communication style, your daily habits, your anxieties, and your ambitions. It knows what you’re working on, who you’re frustrated with, and what keeps you up at night.
That information deserves better than a cloud server you can’t audit and a privacy policy you won’t read.
Local-first AI isn’t just a technical architecture. It’s a statement about who owns your digital life. About whether your most private thoughts should be someone else’s training data. About whether convenience should always win over control.
We think the answer should be you. Your data. Your device. Your rules.
BrainMox is an AI agent with persistent memory, local-first privacy, and real identity. Learn more at brainmox.com.